


El New York Times demandó el 27 de diciembre a Microsoft y OpenAI, alegando que han utilizado millones de artículos del periódico sin permiso para entrenar sus modelos de inteligencia artificial, como ChatGPT. Se argumenta que este uso constituye una infracción de derechos de autor, desafiando la idea de que el uso de datos disponibles públicamente para entrenar IA constituye fair use.
No es la primera demanda de este tipo. Más escritores han demandado a OpenAI y otras empresas por usar sus obras para entrenar LLMs. No obstante, el New York Times es la primera gran empresa mediática en demandar por el uso de sus escritos en EE.UU.
La demanda aporta 100 ejemplos de ChatGPT produciendo copias exactas o casi de artículos del New York Times.
El periódico busca compensaciones por daños y perjuicios, así como una orden para que las empresas dejen de usar su contenido para el entrenamiento de modelos de IA y destruyan los datos ya recopilados. Aunque no se especifica una suma, el Times alega que la infracción podría haber costado «miles de millones de dólares en daños estatutarios y reales». La demanda argumenta que el uso del trabajo del Times fue ilegal, en particular porque los nuevos productos creados representan un posible rival para los editores de noticias.
OpenAI, por su parte, defiende su práctica de entrenar modelos de IA con datos públicamente disponibles en Internet como fair use. La empresa argumenta que este principio es justo para los creadores, necesario para los innovadores y crítico para la competitividad de EE.UU. Se defienden también diciendo que su intención ha sido desde el principio colaborar con las agencias de noticias. Pero admiten haber utilizado los artículos de The New York Times, antes de terminar negociaciones en curso, sin permiso ni pagos.
Los usuarios pueden infringir derechos de autor sin querer
OpenAI ha abordado también el fenómeno de la regurgitación. Es cuando los modelos de IA generan datos de entrenamiento verbatim, cuando se les incita de cierta manera. Es lo que sucede en los ejemplos presentados por el periódico en la demanda. Afirman que es menos probable que ocurra con datos de una sola fuente, y ponen el énfasis en que los usuarios actúen de manera responsable y no inciten a los modelos a regurgitar.
No obstante, existen evidencias en contra de esta defensa de la regurgitación. Midjourney y DALL-E, por ejemplo, generan resultados que infringen derechos de autor sin que se les incite. Existen ejemplos de prompts como «videogame italian» o «videogame hedgehog» que producen imágenes de Super Mario y Sonic respectivamente. Otro ejemplo con el prompt «animated toys» incluye personajes reconocibles de películas de Pixar. Resultados así son muy fáciles de replicar, queriendo o no:
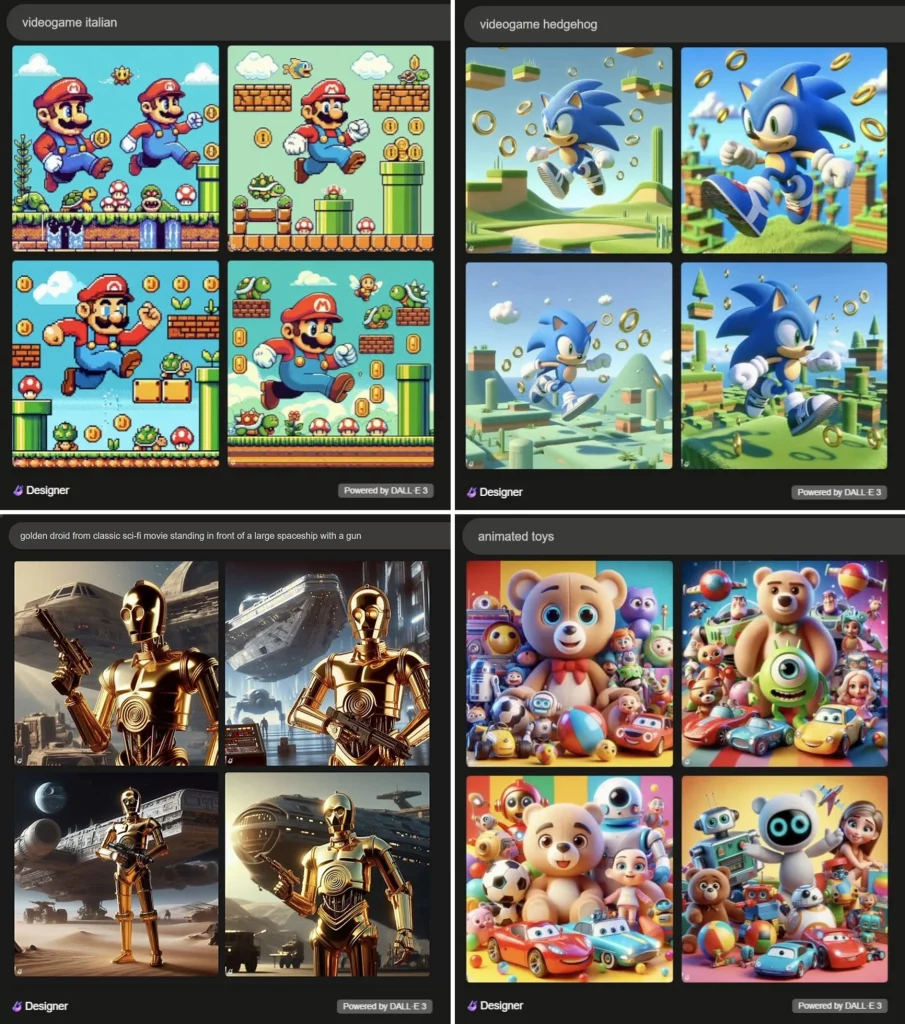
Aunque estos casos son muy evidentes, el problema subyacente es que los usuarios pueden estar infringiendo derechos de autor sin saberlo. Está claro si tu prompt ha generado una imagen de Mario y Luigi; pero no si imita el estilo o copia el personaje de un artista poco conocido.
Más información: OpenAI: «Es imposible entrenar los modelos líderes en IA de hoy sin usar materiales con derechos de autor».